Speech to Text
Subtitle Edit can automatically transcribe audio to text using Whisper-based and other modern speech recognition engines.
- Menu: Video → Speech to text…
Supported Engines
| Engine | Platform | Notes |
|---|---|---|
| Whisper CPP | Windows, Linux, macOS | Local CPU engine. On Windows the cuBLAS (NVIDIA CUDA) and Vulkan GPU backends can also be selected from the Whisper CPP backend dropdown. |
| Purfview Faster Whisper XXL | Windows, Linux | Fast local engine, often used with NVIDIA CUDA |
| Whisper CTranslate2 | Windows, Linux (x64), macOS (Apple Silicon) | CPU / NVIDIA CUDA depending on installation; CUDA requires CUDA 12.x |
| Whisper Const-me | Windows | DirectX-based engine |
| Whisper OpenAI | All | Python-based OpenAI Whisper workflow |
| OpenAI Compatible Server | All | Connect to any OpenAI-compatible speech-to-text endpoint |
| Qwen3 ASR CPP | Windows, Linux | Local Qwen3 ASR engine with downloadable GGUF models |
| Crisp ASR | Windows, Linux, macOS | Single engine with selectable backends: Parakeet, Canary, Cohere, Fire Red, GLM, Granite, Qwen3, Mega, Omni, Kyutai |
Engines and models are downloaded automatically on first use.
SE5 Engine Notes
- Whisper CPP is shown as a single entry; the CPU / cuBLAS / Vulkan backends are selected from a secondary dropdown when Whisper CPP is selected.
- Qwen3 ASR CPP includes 0.6B and 1.7B model options, plus a forced-aligner model used for timing workflows.
- Crisp ASR is exposed as one engine that wraps multiple backends (Parakeet, Canary, Cohere, Fire Red, GLM, Granite, Qwen3, Mega, Omni, Kyutai). Pick the backend from the Crisp ASR backend dropdown.
- A Forced aligner option is shown for Crisp ASR backends and exposes the built-in aligner, Canary CTC, Qwen3, and the wav2vec2 zoo (12 language-specific CTC aligners that run on top of any Crisp ASR backend).
- Several newer engines support automatic language selection.
- Each engine can have separate advanced command-line parameters.
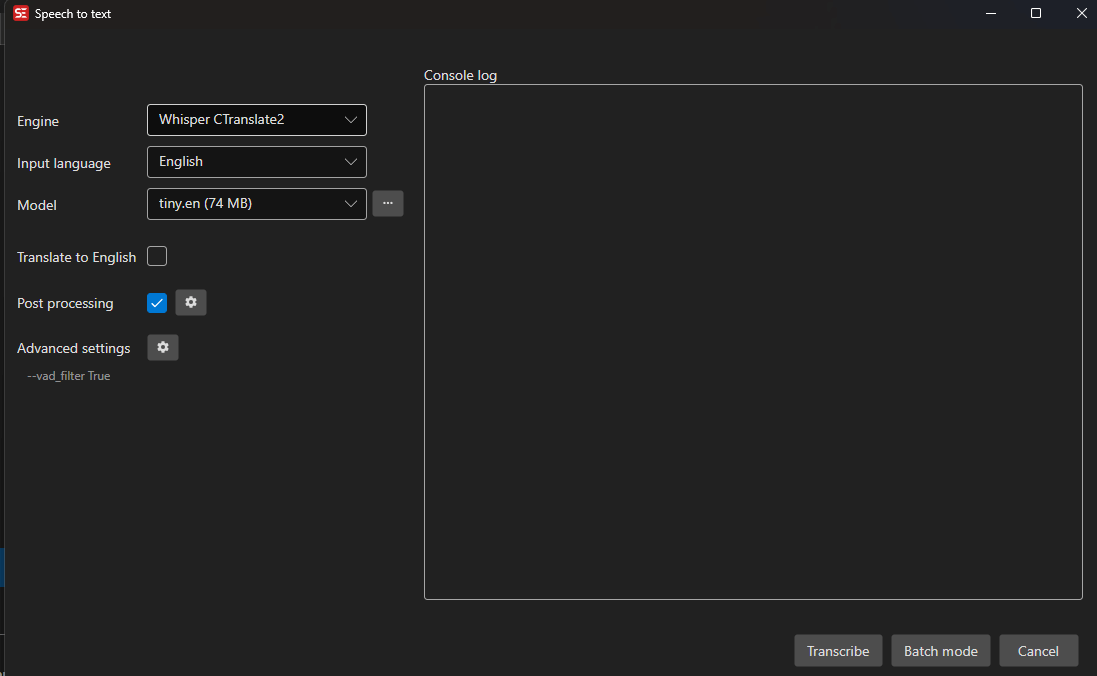
How to Use
- Open a video file in Subtitle Edit
- Go to Video → Speech to text…
- Select an Engine from the dropdown
- Select a Model (larger models usually improve accuracy but take more time and disk space)
- Select the Language of the audio, or use auto-language when the selected engine supports it
- Optionally enable:
- Translate to English — Translate non-English audio to English
- Adjust timings — Post-process timing using waveform data
- Post-processing — Fix casing, merge lines, add periods, etc.
- Click Transcribe
Models
Each engine has its own set of models. Common model sizes:
- tiny — Fastest, least accurate
- base — Good balance for quick work
- small — Better accuracy
- medium — High accuracy
- large / large-v2 / large-v3 — Best accuracy, slowest
Models ending in .en are English-only and perform better for English audio.
Batch Mode
Transcribe multiple video files at once:
- Click Batch mode
- Add video files
- Click Transcribe
- Results are saved as
.srtfiles next to the video files
Advanced Settings
Click the Advanced button to configure custom command-line arguments for the Whisper engine:
- Use VAD (voice activity detection) for better timing
- Highlight spoken words in the transcript
- Adjust temperature or other model parameters
Advanced settings are stored per engine, so you can keep separate parameters for Whisper CPP, Qwen3 ASR, Crisp ASR, and other engines.
Post-Processing Settings
Click the Post-processing button to configure:
- Adjust timings (using waveform peak data)
- Fix short durations
- Fix casing
- Add periods
- Merge short lines
- Split long lines
- Change underline to color (useful for highlight spoken words)
Console Log
The console log at the bottom shows real-time output from the Whisper process, useful for debugging issues.
Tips
- For NVIDIA GPU users, use the Whisper CPP cuBLAS backend or Purfview Faster Whisper XXL for fastest transcription
- If you get “CUDA out of memory” errors, try a smaller model
- The
--standardparameter is automatically added for Purfview Faster Whisper XXL - You can re-download an engine by right-clicking the engine area
- If a new engine has no model installed yet, let Subtitle Edit download both the engine and the selected model before starting transcription